
To build our first Recipe, we need to choose one (or more) selectors. Free and Batch Data Collector provide a tool to help define selectors “interactively”, but you’ll still need to know the basic of how they function.
Source code always starts with a main selector, and then continues with a selector for each column of the record to be built. As we begin to further explain how selectors work, let’s use the following simplified source code for the remainder of this chapter:
<html> <header> <title>Yearly budget and expenses</title> </header> <body> <div id="firstBlock"> This page contains counts updated thru <strong>September 25th, 2019</strong> relating to budgets and expenses. <span>Total Budget: <i>12,000,000 Euro</i></span><br/> <span>Total Expenses: <i>6,000,000 Euro</i></span> </div> <table id="year2017"> <tr><td>Month</td><td>Relative (Euro)</td><td>Absolute (Euro)</td></tr> <tr><td>Jan-Feb</td><td>1,000,000</td><td>1,000,000</td></tr> <tr><td>Mar-Apr</td><td>1,000,000</td><td>2,000,000</td></tr> <tr><td>May-Jun</td><td>1,000,000</td><td>3,000,000</td></tr> <tr><td>Jul-Aug</td><td>1,000,000</td><td>4,000,000</td></tr> <tr><td>Sep-Oct</td><td>1,000,000</td><td>5,000,000</td></tr> <tr><td>Nov-Dec</td><td>1,000,000</td><td>6,000,000</td></tr> </table> <div class="finalcredit">Final Credit: 6,000,000 Euro</div> <br/><br/> <table> <tr><td>Month</td><td>Relative (Euro)</td><td>Absolute (Euro)</td></tr> <tr><td>Jan-Feb</td><td>500,000</td><td>500,000</td></tr> <tr><td>Mar-Apr</td><td>500,000</td><td>1,000,000</td></tr> <tr><td>May-Jun</td><td>500,000</td><td>1,500,000</td></tr> <tr><td>Jul-Aug</td><td>1,000,000</td><td>2,500,000</td></tr> <tr><td>Sep-Oct</td><td>1,000,000</td><td>3,500,000</td></tr> <tr><td>Nov-Dec</td><td>1,000,000</td><td>4,500,000</td></tr> </table> <div class="finalcredit">Final Credit: 1,500,000 Euro</div> <br/> </body>
The code will generate a page with content similar to the following:
This page contains counts updated thru September 25th, 2019 relating to budgets and expenses.
Total Budget: 12,000,000 Euro
Total Expenses: 6,000,000 Euro
| Month | Relative (Euro) | Absolute (Euro) |
| Jan-Feb | 1,000,000 | 1,000,000 |
| Mar-Apr | 1,000,000 | 2,000,000 |
| May-Jun | 1,000,000 | 3,000,000 |
| Jul-Aug | 1,000,000 | 4,000,000 |
| Sep-Oct | 1,000,000 | 5,000,000 |
| Nov-Dec | 1,000,000 | 6,000,000 |
Final Credit: 6,000,000 Euro
| Month | Relative (Euro) | Absolute (Euro) |
| Jan-Feb | 500,000 | 500,000 |
| Mar-Apr | 500,000 | 1,000,000 |
| May-Jun | 500,000 | 1,500,000 |
| Jul-Aug | 1,000,000 | 2,500,000 |
| Sep-Oct | 1,000,000 | 3,500,000 |
| Nov-Dec | 1,000,000 | 4,500,000 |
Final Credit: 1.500.000 Euro
The source code is quite short and contains two types of macro-elements:
– loose elements scattered throughout the text;
– grouped elements, for example in a table or list.
Choosing a main block or recursive element for a new Recipe allows you to define the spectrum of analysis and visibility for your data extraction. If the main block chosen were the first table, the child fields accessible starting from the main block would be the seven rows and the twenty-one cells of the table itself. No more, no less. This would then allow Free / Batch Data Collector to identify one or more child tags to be connected (here, the rows and columns of the table) since they are children of the chosen tag table.
To widen the field of code visibility to the entire page, which would allow us to connect certain random elements, we’d need to broaden our view by ascending to the body or even html tag level, the latter being the parent of all tags. Doing so, however, means that we will lose the ability to identify and use a recursive element.
The moral of the story here is that correctly identifying the parent element of repetitive tags as your main block is paramount when extracting similar objects, things like rows of a table, columns of a row, bullets in a list, links within a specific paragraph, and so on. By accurately identifying the “Main block or recursive element” you’ll be able to create extractions by iteration, collecting countless lines that structurally follow one another with little-to-no effort.
Main Block or Recursive Element
The parent element is what we want to use when writing a recipe. It’s important that we try to identify the right parent element and not just use html or body, particularly if you want to perform the extraction of a table or a list, or in instances where you have a tag that, once placed inside another tag, may occur more than once within the parent tag.
In our example
table#year2017 tr
is the parent element of all the rows within it, its children.
What you see bolded above is, and we cannot stress this enough, a CSS Selector that identifies the parent object of the underlying elements that we will hook the tag tr found inside the table with id year2017.
Set Columns
The columns of a Recipe can be dedicated to information scattered throughout the web page, or to recurring elements contained in a parent element. Again using the example above, we can extract the information found in each row of the table year2017 by generating 3 columns and hooking them to the node td with Instance No. set respectively to 0, 1 and 2 (the first, the second, and the third).
Here’s how the completed Recipe would look:
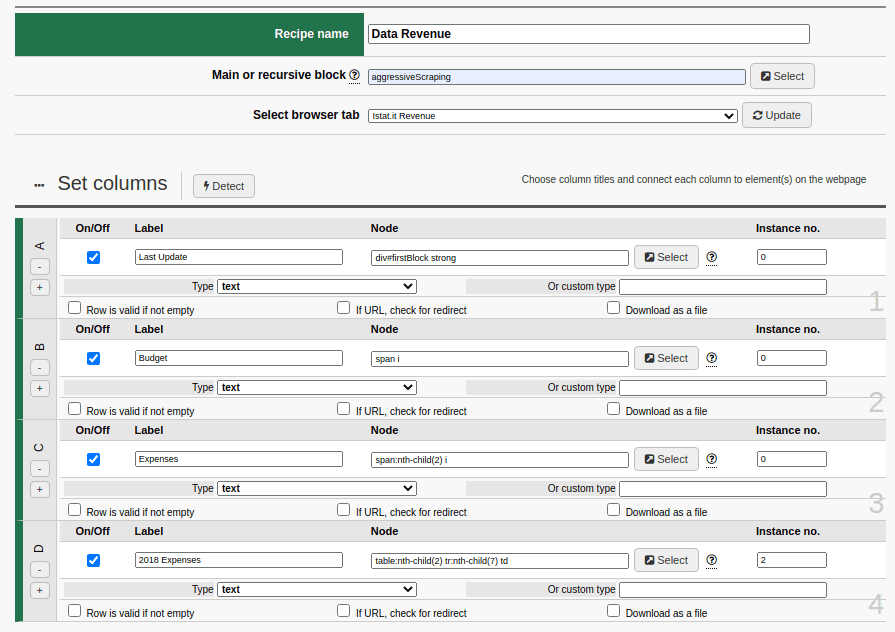
with just a few settings you can extract tons of information
Let’s take a moment to recap what we’ve learned, even if it feels like it’s overkill.
Since the rows to be extracted for the first of the two tables in our example are all children of the same table element, we can identify the main block or recursive element with tr.
The selected table contains three columns, which can be recreated with the “Add Column” button located at the bottom of the Recipe creation area.
The columns must then be activated with the corresponding check mark located just to the left of each. The elements to be connected are all td columns, so we need to type td in each Node field. Then, to point to the right column, we need to set each Instance no.
The first tag found by scrolling the code from the top always has an index of 0. Thus, the elements of interest in this example will have indexes of 0, 1 and 2. Last, in the Type drop-down we’ll choose text, which only returns the string of characters seen on the screen.
A Recipe for Extracting Tables
Using the same logic, a Recipe for extracting tables could be generalized. Let’s assume we want to capture 5-column tables. Our main block or recursive element would be a generic “table tr“.
The Recipe would contain 5 columns, each indicating the Node “td“. The Instance No. fields will contain values from 0 to 4.
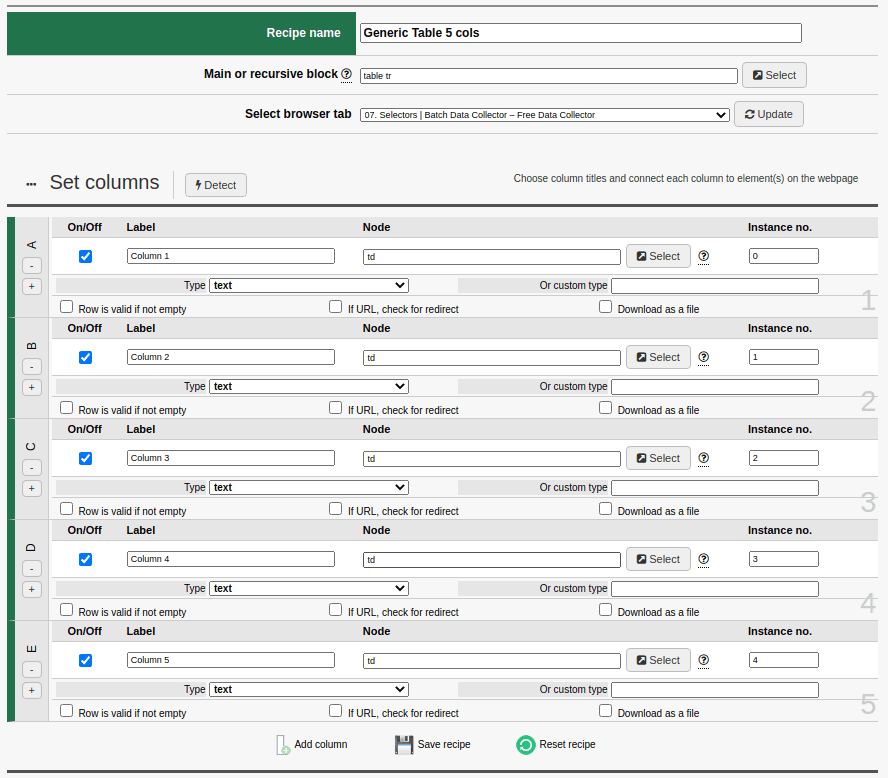
If you’re savvy you may have noticed that a generic Recipe like this would effectively capture all rows from all tables present in the source code in order, starting from the first and continuing on until no more tables are found. And that’s not all: it would combine all the lines into one giant table. The only limiter here would be the number of columns, in this example set to 5.
Obviously there are specific Selectors you can use to indicate which tag table you want to use. If you’re not specific, the code extraction visibility spectrum will be wider and will include all instances of tag table found on the page.
Extracting Loose Data Elements
Continuing with the example above, we may wish to obtain a table that looks like this:
| Last Update | Budget | Expenses | 2018 Expenses |
| September 25th, 2019 | 12,000,000 Euro | 6,000,000 Euro | 4,500,000 Euro |
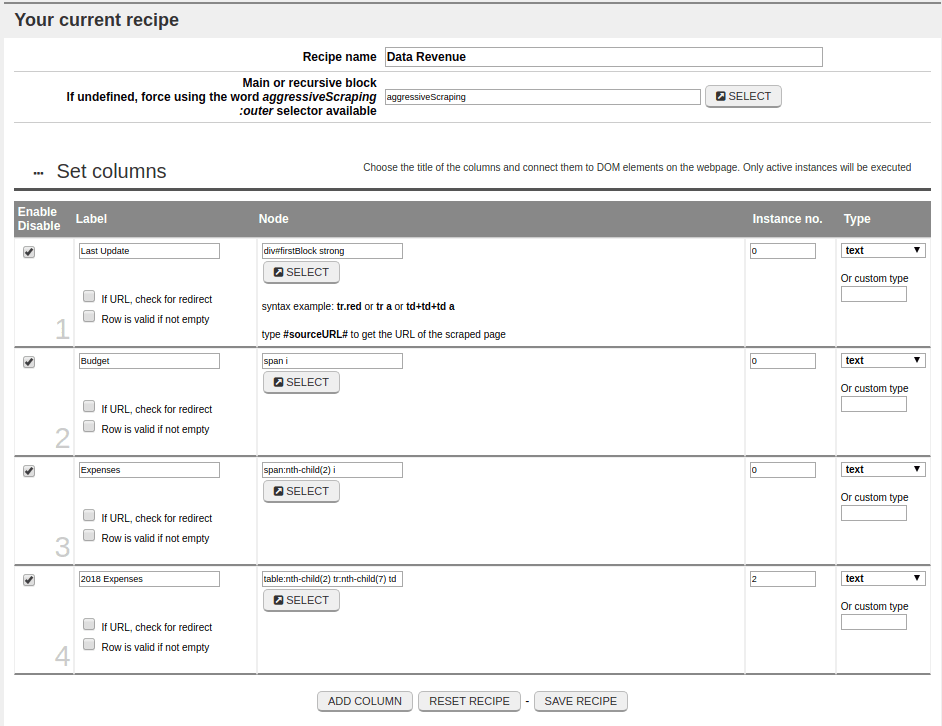
Sarebbe quindi necessario raccogliere informazioni da nodi non contigui del codice sorgente. A questo proposito, il Blocco principale o elemento ripetitivo diventerebbe “html” o “body“. Free e Batch Data Collector prevedono anche la possibilità di inserire una parola chiave flessibile che ricerchi automaticamente il blocco principale. Si tratta di “aggressiveScraping“. Here we’ll need to collect information from non-contiguous nodes in the source code. To do so, the main block or recursive element would become “html” or “body“. Free and Batch Data Collector also allow you to insert a predefined flexible keyword that automatically searches for the page’s main block, which we’ve called “aggressiveScraping“.
Whatever you choose, you’ll need to define four columns, each labeled “Update”, “Budget”, “Expenses” and “2018 Expenses”. The nodes to be assigned, in order, will be:
- div#firstBlock strong
for “September 25th, 2019”. - span i
for “12,000,000 Euro”. - span+span i
to select the second “span” in code order, and therefore the tag “i” contained within, and therefore “6,000,000 Euro”. - table+table tr+tr+tr+tr+tr+tr+tr td+td+td
to select the third column of the seventh line of the second table.
While this is somewhat intuitive, and similar to how you’d play Battleship, there are ways to further simplify the Node. For example, table+table tr+tr+tr+tr+tr+tr+tr td+td+td can also be expressed as
table:nth-child(2) tr:nth-child(7) td
and entering the number 2 in the Instances No. field.
nth-child, instead, is a commonly-used standard CSS Selector that allows you to quickly grab any sub-node that may otherwise be difficult to reach (perhaps it wasn’t uniquely identified by an id or is not part of a class).
Below is the Recipe in its entirety:
In the next section we’ll introduce a more complete list of CSS Selectors that should help you with any troubles, small or large, you may inevitably come across when defining of the most appropriate Selector for your Recipe.